英特尔(Intel
- 编辑:足球滚球app下载 -英特尔(Intel
 为了继续促进AI切割模型的创新发展,英特尔一直与领先的现代部队保持着深入的合作。我们很高兴地宣布,英特尔AI的新升级解决方案完全涵盖了PC客户端,边缘计算,智能机舱和其他方案,该解决方案为首次发布QWEN3系列Big Model的发布提供了技术支持。新的Qwen3系列大型模型的五个亮点:1。在 - 深度优化的MOE模型中,最终Qwen32出色地扩展。 Day 0 supports big models on NPU for the first time, providing better performance and power consumption performance 3. Fine-tuning of the end side, improving model intelligence, and optimizing user experience 4. Dynamic sparse attention empowers qwen3 long context windows, unlocking new applications of end side agent 5. Ecosystem, Day0 Supports The Magic Community Ollama in this new generation of Tongyi Qianwen QWEN3 series Models Open Source, The Most Eye-动机的事物是30B参数量表MOE混合特殊模型(专家晕)(QWEN3-30B-MOE-A3B)。借助高级动态可调节的混合体系结构,该模型在有效提高计算效率方面具有出色的性能,从而在本地设备(客户端和侧面设备)上提供了广泛的应用程序。但是,在扩展和消耗系统一般资源的过程中很难。为了应对这些挑战,英特尔和阿里巴巴共同努力为MOE模型进行全面的技术适应。通过实施多种约会技术,OpenVinotm Tool Suite已在Intel硬件平台上成功地使用Mahusay部署了QWEN模型。具体而言,与同一参数量表的密集模型相比,在ARL-H 64G存储器中部署的30B参数量表MOE模型已达到33.97代币/s 1的吞吐量,并实现了显着的性能。英特尔软件方法接近FUSI关于稀疏混合专家模型体系结构(稀疏MOE)的融合,3B激活模型的调度和涂料存储器以及不同专家之间的负载平衡。这些技术可以帮助更多的MOE模型在英特尔平台上很好地部署。 QWEN3系列模型此时发布主要集中在具有中小型参数的密集LLM体系结构上,参数尺度从0.6B到32B,可以适应一系列糟糕的硬件资源,并满足不同使用方案的需求。 Intel's CPU, GPU, and NPU architectures are fully fitted with the QWEN series model, optimized for model expansion, using Intel Openvinotm Tool Suite and Pytorch Tool to achieve excellence for expanding the entire series/200 series) and Intel Rukuan ™ A-Sieries Graphics cards and series series) RU RU RU RU RU RU RU RU RUCUAN ™ A-SIERIES B-SERIES GRAPHICS CARDS.值得一提的是,英特尔首次为NPU模型发布第0天,反映R在Intel和开放的Ecosy系统之间的合作,并为不同的模型参数和应用程序方案提供了更多样化和目标平台的支持。对于从0.6B到8B的中小型参数的小型PAR模型,吞吐量为36.68代币2。在Intel Lunar Lake NPU平台和Intel OpenVinotm工具套件的帮助下,您可以保持低能消耗,同时获得良好的性能。同时,英特尔继续在Core Ultra的IGPU平台上为模型带来出色的性能。对于少量型号,最大值为66个令牌/S2,具有FP16精度,对于少量型号,最大值为35.83代币/S2,具有INT4精度。开发人员可以根据适当的使用情况找到准确性和性能的最佳组合。为了支持具有更强计算能力的英特尔Ruixuan B系列图形卡,QWEN3-8B型号可以实现70.67代币/S3。开发人员可以立即欣赏晚期的额外组合St Modelor和出色的Intel平台功能,并享受剪切技术带来的效率和便利。作为生成AI模型中的轻量级播放器,0.6B小LLM的体积具有灵活,有效的扩展的好处以及重复和更新的能力。但是,在实际应用过程中,人们通常会担心自己的知识的深度和程度以及处理复杂任务的能力。通过使用特定数据集攻击小LLM,模型的智能可以改善,并且可以优化用户体验。到目前为止,基于不舒服并包含面部参数,可以很好地调整剧情(PEFT PEFT),Intel已建立了完整的修整解决方案,以使模型更聪明,Andai PC应用程序确实成为了关怀和智能的助手。
在发布的QWEN3模型中,我们注意到其上下文长度的LLM功能有了显着提高。面对有限的计算来源,英特尔提供了如何有效地使用模型的长期环境来防止扩大计算资源消耗的增长的解决方案,从而将LLM应用程序方案扩展到客户端。基于动态广泛的关注,我们可以使处理长上下文窗口的速度加倍,同时确保准确性损失。在此解决方案中,QWEN3-8B模型可以在英特尔LNL平台上实现32K上下文长度。
这种上下文的长度功能为终端代理的更多新应用打开了。将SA更强的QWEN3代理和代码组合在一起,以及对MCP协议的增强支持,它允许基于端端大型模型来调用MCP服务。可以首次开发各种AI PC代理。该视频显示,在Intel AI PC中,通过基于QWEN3-8B型号调用Biyou Technology Chatppt.cn MCP服务来自动PPT编队的过程。
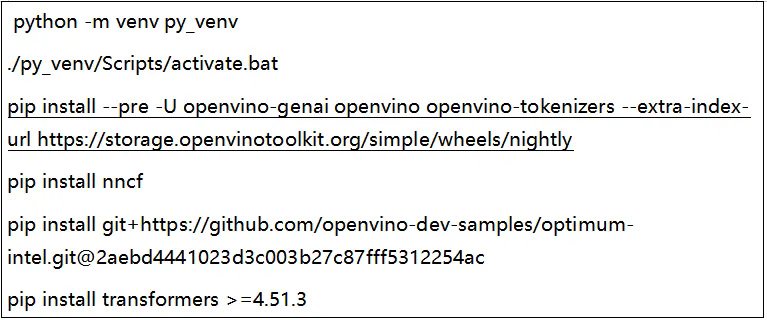
ang intel ay patuloy na yakapin ang bukas na mapagkukunan ng ekosistema, at ang Intel na -optimize na bersyon ng Ollama ay sumusuporta din sa mga modelo ng serye ng QWEN3 kabilang ang mga modelo ng MOE sa lalong madaling panahon, na nagpapahintulot sa mga developer na gamitin ang Ollama Framework upang makabuo ng mga matalinong aplikasyon batay sa mga modelo ng qwen3系列SA Intel客户端平台(Tulad ng MGA Intel Core Ultra Ai PC,Intel Ruixuan A/B系列图形卡)。 Olllama的版本还提供了MAPAI模型下载源的建立,该源使本地开发人员可以从MPAI社区更好地下载和部署安装软件包和模型。英特尔与汽车端舱中新发布的QWEN3系列车型非常匹配。基于英特尔的车载软件和硬件解决方案(包括第一代英特尔AI增强车辆指定软件(SDV)SOC,第二代SDV SOC NPU仅在上海汽车展上发布,而Intel Ruixuan™Intel Ruixuan™In In Indival Independ Independ Independial GraphicS卡),英特尔可以尽快提供QWEN3的Intel模型,从而尽快避免使用,从而充分获得对局部疾病计算的局部计算。其中,第二代SDV SOC首先在自动化行业采用了多型粒子构造,与上一代相比,它具有生成的和多模式的AI性能,可以提高10次乘4倍,这是自动型AI的经验,例如在机舱中的实时对话,自然语言接触和复杂的指导。下面的启动指南将以QWEN3-8B为例,以介绍如何使用OpenVino™的Python API在Intel平台(GPU,NPU)上运行QWEN3系列模型。 You can also refer to the complete example below: https://github.com/openvinotoolkit/openvino_Notebooks/tree/latest/Notebooks/llm-chatbothttps://github.com/openvinotoolkit/openvino.genai/tree/master/sammps/python/text_generation is the first step -Pemployment of Python基于以下命令的模型。步骤2,下载Modelo并在部署模型之前进行转换,我们必须首先转换原始的Pytorch模型以开发OpenVinotm图形格式并压缩它以实现较轻的扩展和最佳性能。借助最佳CLI提供的命令行工具,我们可以单击一键完成格式转换模型和权重数量任务。请参阅ptimum-cli使用方法:https://docs.openvino.ai/2024/lealen-openvino/llm_inference_guide/genai-nodel-preparation.html补充,我们建议使用以下参数在NPU中开发npu以实现绩效和利润的平衡。第三步是部署模型。 OpenVinotm当前为大语言模型提供了两种扩展解决方案。如果您习惯于IntryStrymer库面对部署模型并希望体验更丰富的功能,建议使用基于TH的最佳工具E Python接口生成任务。如果您想尝试更强烈的性能或轻巧的扩展方法,那么Genai API是唯一的选择。它支持Python和C ++编程语言,并且安装容量小于200MB。 ·最佳智能部署示例·genai api部署的示例在这里您可以更改设备名称以轻松将模型部署到NPU。 ·此外,ModelsCope中的Ollama软件包(https://www.modelscope.cn/models/intel/ollama/summary)准备下载Now1。通过在SKU1平台上使用OpenVino Framework版本2025.1.0测试的性能数据。计算工作由集成图形卡(IGPU)完成。这些测试在处理INT4混合动力车的精度设置下处理1K输入时,评估了内存的痕迹,第一个令牌延迟和平均吞吐量。每个测试加热后3次进行,并选择中间值作为报告数据。 。 32。功率极限持续时间(w):70,关键软件版本:OpenVino 2025.2.0-DEV20250427,OpenVino-Genai 2025.2.0.0.0.0.0.0-dev20250427,变压器4.49.0)2。使用OpenVino Framework版本2025.1.0在SKU上测试性能数据,该版本是集成图形卡(IGPU)或Neural Crocessiy(INP)的SKU(npo)。该测试在处理INT4混合动力,IT8通道重量准确性和FP16精度设置下处理1K输入时评估记忆的痕迹,第一个令牌延迟和平均吞吐量。每个测试加热后3次进行,并选择中间值作为报告数据。 。 32。防守者:跑步,长时间持续套餐限制(w):30,功率短(W):37,关键软件版本:OpenVino 2025.2.0-DEV20250427,OpenVino-Genai 4.49.0)3。绩效数据是在SKU3上测试SKU3,使用OpenVino Framework frameworker Framework 2025.1.0及其绘制的映射构图,并置于看台上,站立了看台。该测试检查了在INT4混合精度,INT8体积和FP16的精度设置下处理1K输入时,内存,第一个令牌延迟和平均吞吐量。加热阶段后三次进行每个测试,并选择中间值作为报告数据。 。 32。2025。有关更多信息,请访问intel.com/performanceIndex。基于第二代英特尔AI增强SDV SOC GPU+NPU和MBL I7-13800HAQ CPU+GPU(涡轮增压)的内部预测,AI性能可提高十倍。
为了继续促进AI切割模型的创新发展,英特尔一直与领先的现代部队保持着深入的合作。我们很高兴地宣布,英特尔AI的新升级解决方案完全涵盖了PC客户端,边缘计算,智能机舱和其他方案,该解决方案为首次发布QWEN3系列Big Model的发布提供了技术支持。新的Qwen3系列大型模型的五个亮点:1。在 - 深度优化的MOE模型中,最终Qwen32出色地扩展。 Day 0 supports big models on NPU for the first time, providing better performance and power consumption performance 3. Fine-tuning of the end side, improving model intelligence, and optimizing user experience 4. Dynamic sparse attention empowers qwen3 long context windows, unlocking new applications of end side agent 5. Ecosystem, Day0 Supports The Magic Community Ollama in this new generation of Tongyi Qianwen QWEN3 series Models Open Source, The Most Eye-动机的事物是30B参数量表MOE混合特殊模型(专家晕)(QWEN3-30B-MOE-A3B)。借助高级动态可调节的混合体系结构,该模型在有效提高计算效率方面具有出色的性能,从而在本地设备(客户端和侧面设备)上提供了广泛的应用程序。但是,在扩展和消耗系统一般资源的过程中很难。为了应对这些挑战,英特尔和阿里巴巴共同努力为MOE模型进行全面的技术适应。通过实施多种约会技术,OpenVinotm Tool Suite已在Intel硬件平台上成功地使用Mahusay部署了QWEN模型。具体而言,与同一参数量表的密集模型相比,在ARL-H 64G存储器中部署的30B参数量表MOE模型已达到33.97代币/s 1的吞吐量,并实现了显着的性能。英特尔软件方法接近FUSI关于稀疏混合专家模型体系结构(稀疏MOE)的融合,3B激活模型的调度和涂料存储器以及不同专家之间的负载平衡。这些技术可以帮助更多的MOE模型在英特尔平台上很好地部署。 QWEN3系列模型此时发布主要集中在具有中小型参数的密集LLM体系结构上,参数尺度从0.6B到32B,可以适应一系列糟糕的硬件资源,并满足不同使用方案的需求。 Intel's CPU, GPU, and NPU architectures are fully fitted with the QWEN series model, optimized for model expansion, using Intel Openvinotm Tool Suite and Pytorch Tool to achieve excellence for expanding the entire series/200 series) and Intel Rukuan ™ A-Sieries Graphics cards and series series) RU RU RU RU RU RU RU RU RUCUAN ™ A-SIERIES B-SERIES GRAPHICS CARDS.值得一提的是,英特尔首次为NPU模型发布第0天,反映R在Intel和开放的Ecosy系统之间的合作,并为不同的模型参数和应用程序方案提供了更多样化和目标平台的支持。对于从0.6B到8B的中小型参数的小型PAR模型,吞吐量为36.68代币2。在Intel Lunar Lake NPU平台和Intel OpenVinotm工具套件的帮助下,您可以保持低能消耗,同时获得良好的性能。同时,英特尔继续在Core Ultra的IGPU平台上为模型带来出色的性能。对于少量型号,最大值为66个令牌/S2,具有FP16精度,对于少量型号,最大值为35.83代币/S2,具有INT4精度。开发人员可以根据适当的使用情况找到准确性和性能的最佳组合。为了支持具有更强计算能力的英特尔Ruixuan B系列图形卡,QWEN3-8B型号可以实现70.67代币/S3。开发人员可以立即欣赏晚期的额外组合St Modelor和出色的Intel平台功能,并享受剪切技术带来的效率和便利。作为生成AI模型中的轻量级播放器,0.6B小LLM的体积具有灵活,有效的扩展的好处以及重复和更新的能力。但是,在实际应用过程中,人们通常会担心自己的知识的深度和程度以及处理复杂任务的能力。通过使用特定数据集攻击小LLM,模型的智能可以改善,并且可以优化用户体验。到目前为止,基于不舒服并包含面部参数,可以很好地调整剧情(PEFT PEFT),Intel已建立了完整的修整解决方案,以使模型更聪明,Andai PC应用程序确实成为了关怀和智能的助手。
在发布的QWEN3模型中,我们注意到其上下文长度的LLM功能有了显着提高。面对有限的计算来源,英特尔提供了如何有效地使用模型的长期环境来防止扩大计算资源消耗的增长的解决方案,从而将LLM应用程序方案扩展到客户端。基于动态广泛的关注,我们可以使处理长上下文窗口的速度加倍,同时确保准确性损失。在此解决方案中,QWEN3-8B模型可以在英特尔LNL平台上实现32K上下文长度。
这种上下文的长度功能为终端代理的更多新应用打开了。将SA更强的QWEN3代理和代码组合在一起,以及对MCP协议的增强支持,它允许基于端端大型模型来调用MCP服务。可以首次开发各种AI PC代理。该视频显示,在Intel AI PC中,通过基于QWEN3-8B型号调用Biyou Technology Chatppt.cn MCP服务来自动PPT编队的过程。
ang intel ay patuloy na yakapin ang bukas na mapagkukunan ng ekosistema, at ang Intel na -optimize na bersyon ng Ollama ay sumusuporta din sa mga modelo ng serye ng QWEN3 kabilang ang mga modelo ng MOE sa lalong madaling panahon, na nagpapahintulot sa mga developer na gamitin ang Ollama Framework upang makabuo ng mga matalinong aplikasyon batay sa mga modelo ng qwen3系列SA Intel客户端平台(Tulad ng MGA Intel Core Ultra Ai PC,Intel Ruixuan A/B系列图形卡)。 Olllama的版本还提供了MAPAI模型下载源的建立,该源使本地开发人员可以从MPAI社区更好地下载和部署安装软件包和模型。英特尔与汽车端舱中新发布的QWEN3系列车型非常匹配。基于英特尔的车载软件和硬件解决方案(包括第一代英特尔AI增强车辆指定软件(SDV)SOC,第二代SDV SOC NPU仅在上海汽车展上发布,而Intel Ruixuan™Intel Ruixuan™In In Indival Independ Independ Independial GraphicS卡),英特尔可以尽快提供QWEN3的Intel模型,从而尽快避免使用,从而充分获得对局部疾病计算的局部计算。其中,第二代SDV SOC首先在自动化行业采用了多型粒子构造,与上一代相比,它具有生成的和多模式的AI性能,可以提高10次乘4倍,这是自动型AI的经验,例如在机舱中的实时对话,自然语言接触和复杂的指导。下面的启动指南将以QWEN3-8B为例,以介绍如何使用OpenVino™的Python API在Intel平台(GPU,NPU)上运行QWEN3系列模型。 You can also refer to the complete example below: https://github.com/openvinotoolkit/openvino_Notebooks/tree/latest/Notebooks/llm-chatbothttps://github.com/openvinotoolkit/openvino.genai/tree/master/sammps/python/text_generation is the first step -Pemployment of Python基于以下命令的模型。步骤2,下载Modelo并在部署模型之前进行转换,我们必须首先转换原始的Pytorch模型以开发OpenVinotm图形格式并压缩它以实现较轻的扩展和最佳性能。借助最佳CLI提供的命令行工具,我们可以单击一键完成格式转换模型和权重数量任务。请参阅ptimum-cli使用方法:https://docs.openvino.ai/2024/lealen-openvino/llm_inference_guide/genai-nodel-preparation.html补充,我们建议使用以下参数在NPU中开发npu以实现绩效和利润的平衡。第三步是部署模型。 OpenVinotm当前为大语言模型提供了两种扩展解决方案。如果您习惯于IntryStrymer库面对部署模型并希望体验更丰富的功能,建议使用基于TH的最佳工具E Python接口生成任务。如果您想尝试更强烈的性能或轻巧的扩展方法,那么Genai API是唯一的选择。它支持Python和C ++编程语言,并且安装容量小于200MB。 ·最佳智能部署示例·genai api部署的示例在这里您可以更改设备名称以轻松将模型部署到NPU。 ·此外,ModelsCope中的Ollama软件包(https://www.modelscope.cn/models/intel/ollama/summary)准备下载Now1。通过在SKU1平台上使用OpenVino Framework版本2025.1.0测试的性能数据。计算工作由集成图形卡(IGPU)完成。这些测试在处理INT4混合动力车的精度设置下处理1K输入时,评估了内存的痕迹,第一个令牌延迟和平均吞吐量。每个测试加热后3次进行,并选择中间值作为报告数据。 。 32。功率极限持续时间(w):70,关键软件版本:OpenVino 2025.2.0-DEV20250427,OpenVino-Genai 2025.2.0.0.0.0.0.0-dev20250427,变压器4.49.0)2。使用OpenVino Framework版本2025.1.0在SKU上测试性能数据,该版本是集成图形卡(IGPU)或Neural Crocessiy(INP)的SKU(npo)。该测试在处理INT4混合动力,IT8通道重量准确性和FP16精度设置下处理1K输入时评估记忆的痕迹,第一个令牌延迟和平均吞吐量。每个测试加热后3次进行,并选择中间值作为报告数据。 。 32。防守者:跑步,长时间持续套餐限制(w):30,功率短(W):37,关键软件版本:OpenVino 2025.2.0-DEV20250427,OpenVino-Genai 4.49.0)3。绩效数据是在SKU3上测试SKU3,使用OpenVino Framework frameworker Framework 2025.1.0及其绘制的映射构图,并置于看台上,站立了看台。该测试检查了在INT4混合精度,INT8体积和FP16的精度设置下处理1K输入时,内存,第一个令牌延迟和平均吞吐量。加热阶段后三次进行每个测试,并选择中间值作为报告数据。 。 32。2025。有关更多信息,请访问intel.com/performanceIndex。基于第二代英特尔AI增强SDV SOC GPU+NPU和MBL I7-13800HAQ CPU+GPU(涡轮增压)的内部预测,AI性能可提高十倍。


